")

今日は、詳しくは企業秘密なので言えませんが、Googleのとある研究ユニットに勤めている友人が研究室を訪ねてきました。Google Colabを使って、深層学習で、あるアフリカの言語の言語モデルを作ろうという話になり、ちょっとやってみました。Pre-Trainedの言語モデルで、要は、テキストファイルのその言語のテキストをできるだけたくさん与えれば良いらしいです。Pre-trained(事前学習済み)言語モデルとは、機械に言語データを大量に与えて、その機械にこの単語が来れば、次はこの単語が来そうとか、この位置ではこの語形が来そうとか、重み付けで、学習させたものです。
この際に、品詞やレンマなどの情報やタグ付けは無用で、ただ単に、Unicodeなどで書かれ機械可読な形にしたプレインテキストを大量に与えるだけでいいです。まず事前学習済み言語モデルを作ってしまって、そのあと、レンマや品詞タグ付けなどの形態素解析とか統語解析とか係り受け解析とかOCR(画像と文字とのマッチング)をやると、優れた解析モデル、OCRモデルができるよ、とのことです。
なので、まずは、この言語で、事前学習済み言語モデルを作ってみようとおもいます。ここでいう、モデルとは、理想像みたいないみでなく、ある言語のパターンを機械的に何万例も見せつけられて、だいたいパターンを会得した、疲れ知らずの学習を終えた生徒みたいな感じです。
ここで重要なのは、この機械学習の教育理念は、教科書を与えて、ある言語の文法を教師が丁寧に教えていく、という学習方法ではなく、この生徒に教えるのは、その言語の例文を何万通りも、休む暇もなく見せ続ける、超スパルタで、非人間的な学習方法です。機械なので、そのようなことも簡単にできちゃいます(ただし、電力とかを食う、あと、良いGPUがあった方が良い)。
これをやるにはロボットの生徒が良い設備をもっていることが重要ですが、最近では、GPUがその良い設備となっています。よいGPUがあれば、より早く学習できるわけですが、機械学習で使われるようなNVIDIAのA100のようなGPUだと、安くて定評があるかんじの見た目の某ネットストアでは179万円します(執筆時点)。
この悩みを解決するのが、遠隔で、どこかの企業のすごいコンピュータのGPUを使わせてもらうやり方ですが、Googleでは、Google ColabというJupyter Notebookをクラウド化したかんじの、ひじょうに便利なサービスをやっていて、そこでは、Python言語によるプログラミングでGoogleのGPUを使わせてもらえます。
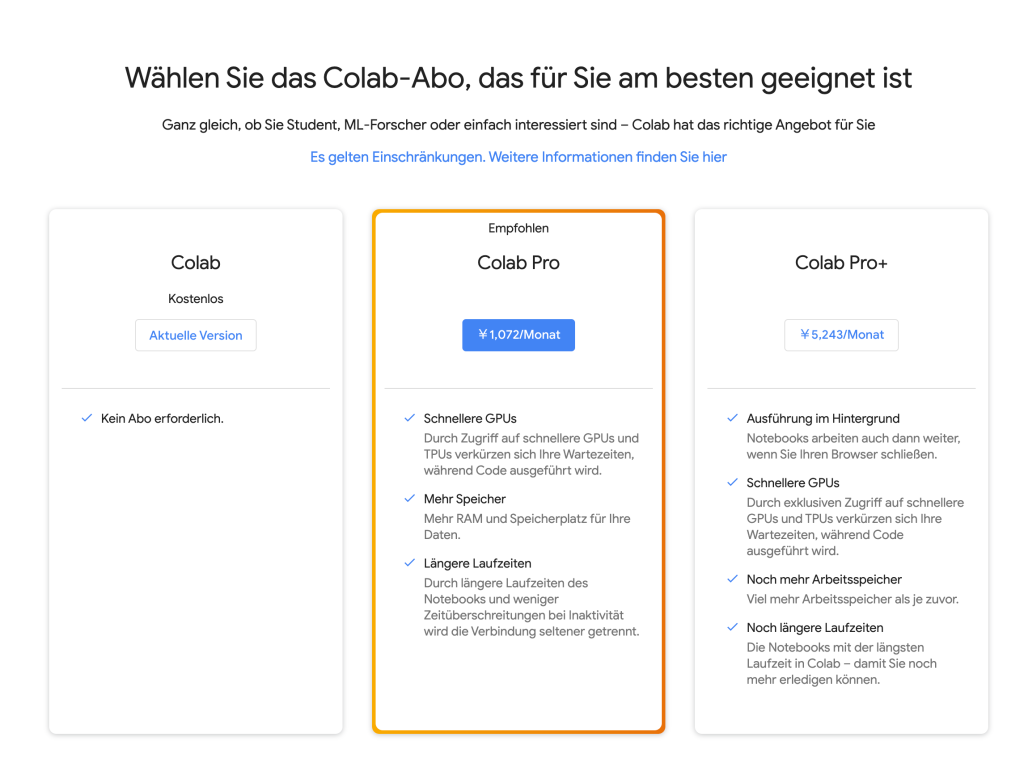
いろんなGPUが使えるらしいですが、無料版だと、まずまずの性能のGPUを割り当てられることばかりです。しかし、有料のサブスクをすると、良いGPUに割り当てられることがおおくあります。
有料サブスクだと2つあって、ProとPro+があります。Proは月額で1000円程度ですが、Pro+は5000円よりも高いなど、かなり値段的に差がでます。もちろんPro+のほうが良いGPUを優先的に割り当てられます。
大学関係者ならGoogle Cloudの大学関係者のプログラムかなにかで、このPro+を安くサブスクする方法があるらしいです。今度やってみようと思います。友達がためしにちょっと言語モデルを作ろうとしたところ、なんとA100が割り当てられました。これはかなりラッキーだそうです。もちろんその友達はPro+をサブスクしています。ここには詳しく書けませんが、かなり具体的な方法を教えてもらったので、早速Collab Pro+で言語モデルを作ってみようと思います。
参考ウェブサイトを以下に挙げます。
Colab Proとは? 無料版との違い、比較表 – ITmedia
あと、Google Collab Proが日本でも使えるようになったのは2021年9月と最近だそうです。Proのほうは新しいサービスなんですね。
コメント